Configuring LLM providers¶
Connect marimo to an LLM via the notebook Settings panel (recommended) or by editing
marimo.toml directly. Prefer going through the notebook settings menu to avoid errors with the config file.
To locate your config file:
The path to marimo.toml is printed at the top of the output.
Model configuration¶
Model roles and routing¶
marimo uses three roles:
chat_model: chat paneledit_model: refactor cells (Cmd/Ctrl-Shift-E) and Generate with AIautocomplete_model: inline code completion
Models are written as provider/model, and the provider prefix routes to the matching config section:
[ai.models]
chat_model = "openai/gpt-4o-mini" # Routes to OpenAI config
edit_model = "anthropic/claude-3-sonnet" # Routes to Anthropic config
autocomplete_model = "ollama/codellama" # Routes to Ollama config
autocomplete_model = "some_other_provider/some_model" # Routes to OpenAI compatible config
Custom models¶
Add custom entries to the model dropdown:
Supported providers¶
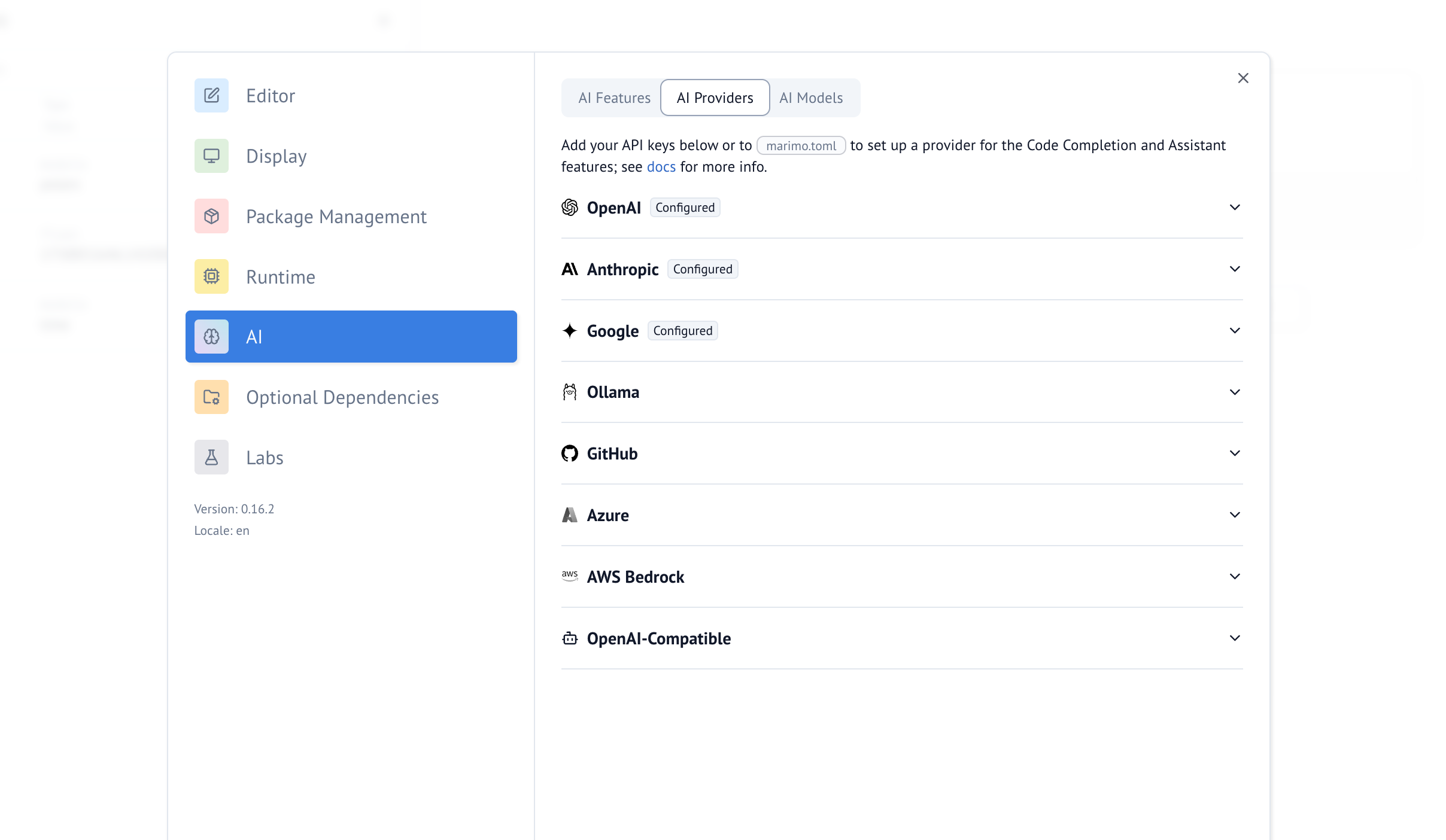
You can configure the following providers:
- Anthropic
- AWS Bedrock
- GitHub
- Google AI
- DeepSeek
- xAI
- LM Studio
- Mistral
- Ollama
- OpenAI
- OpenRouter
- Together AI
- Vercel v0
- and any OpenAI-compatible provider
Below we describe how to connect marimo to your AI provider.
OpenAI¶
Requirements
pip install openai
Configuration
[ai.models]
chat_model = "openai/gpt-4o-mini"
edit_model = "openai/gpt-4o"
# See https://platform.openai.com/docs/models for the latest list
[ai.open_ai]
# Get an API key at https://platform.openai.com/account/api-keys
api_key = "sk-proj-..."
OpenAI-compatible providers
If your model does not start with openai/, it will not be routed to the OpenAI config, and likely will be routed to the OpenAI-compatible config.
Reasoning models (o1, o3, etc.)
These models can incur higher costs due to separate reasoning tokens. Prefer smaller responses for refactors or autocompletion, and review your provider limits.
Anthropic¶
Requirements
- Create an account and key: Anthropic Console
Configuration
[ai.models]
chat_model = "anthropic/claude-3-7-sonnet-latest" # other options: claude-3-haiku, claude-3-opus
# See Anthropic model list: https://docs.anthropic.com/en/docs/about-claude/models
[ai.anthropic]
api_key = "sk-ant-..."
AWS Bedrock¶
AWS Bedrock exposes multiple foundation models via a unified AWS API.
Requirements
pip install boto3- Enable model access in the Bedrock console
- AWS credentials via
aws configure, env vars, or~/.aws/credentials
Configuration
[ai.models]
chat_model = "bedrock/anthropic.claude-3-sonnet-latest"
# Example model families include Anthropic Claude, Meta Llama, Cohere Command
[ai.bedrock]
region_name = "us-east-1" # AWS region where Bedrock is available
# Optional AWS profile name (from ~/.aws/credentials)
profile_name = "my-profile"
Use profile_name for a non-default named profile, or rely on env vars/standard AWS resolution.
Required AWS Bedrock permissions
Ensure your IAM policy allows bedrock:InvokeModel and bedrock:InvokeModelWithResponseStream for the models you plan to use.
Google AI¶
Requirements
- API key from Google AI Studio
pip install google-genai
Configuration
[ai.models]
chat_model = "google/gemini-2.5-pro" # also see gemini-2.0-flash, etc.
# Model list: https://ai.google.dev/gemini-api/docs/models/gemini
[ai.google]
api_key = "AI..."
GitHub Copilot¶
Use Copilot for code refactoring or the chat panel (Copilot subscription required).
Requirements
- Install the gh CLI
- Get a token:
gh auth token
Configuration
My token starts with ghp_ instead of gho_?
This usually happens when you previously authenticated gh by pasting a personal access token (ghp_...). However, GitHub Copilot is not available through ghp_..., and you will encounter errors such as:
bad request: Personal Access Tokens are not supported for this endpoint
To resolve this issue, you could switch to an OAuth access token (gho_...):
- Re-authenticate by running
gh auth login. - Choose Login with a web browser (instead of Paste an authentication token) this time.
OpenRouter¶
Route to many providers through OpenRouter with a single API.
Requirements
- Create an API key: OpenRouter Dashboard
pip install openai(OpenRouter is OpenAI‑compatible)
Configuration
[ai.models]
# Use OpenRouter's model slugs (vendor/model). Examples:
chat_model = "openrouter/openai/gpt-4o-mini"
edit_model = "openrouter/anthropic/claude-3-7-sonnet"
[ai.openrouter]
api_key = "sk-or-..."
base_url = "https://openrouter.ai/api/v1/"
# Optional but recommended per OpenRouter best practices
# extra_headers = { "HTTP-Referer" = "https://your-app.example", "X-Title" = "Your App Name" }
See available models at https://openrouter.ai/models. Make sure to prepend openrouter/ to the model slug (e.g., openrouter/deepseek/deepseek-chat, openrouter/meta-llama/llama-3.1-8b-instruct).
Local models with Ollama¶
Run open-source LLMs locally and connect via an OpenAI‑compatible API.
Requirements
- Install Ollama
- Pull a model
# View available models at https://ollama.com/library
ollama pull llama3.1
ollama pull codellama # recommended for code generation
# View your installed models
ollama ls
- Start the Ollama server:
- Visit http://127.0.0.1:11434 to confirm that the server is running.
Port already in use
If you get a "port already in use" error, you may need to close an existing Ollama instance. On Windows, click the up arrow in the taskbar, find the Ollama icon, and select "Quit". This is a known issue (see Ollama Issue #3575). Once you've closed the existing Ollama instance, you should be able to run ollama serve successfully.
-
Install the OpenAI client (
pip install openaioruv add openai). -
Start marimo:
Important: Use the /v1 endpoint
marimo uses Ollama's OpenAI‑compatible API. Ensure your base_url includes /v1:
Common mistake:
If you see 404s, verify the model is installed with ollama ls and test the endpoint:
- Configure
marimo.toml(or use Settings):
[ai.models]
chat_model = "ollama/llama3.1:latest"
edit_model = "ollama/codellama"
autocomplete_model = "ollama/codellama" # or another model from `ollama ls`
OpenAI-compatible providers¶
Many providers expose OpenAI-compatible endpoints. Point base_url at the provider and use their models.
Common examples include GROQ, DeepSeek, xAI, Together AI, and LM Studio.
Requirements
- Provider API key
- Provider OpenAI-compatible
base_url pip install openai
Configuration
[ai.models]
chat_model = "provider-x/some-model"
[ai.open_ai_compatible]
api_key = "..."
base_url = "https://api.provider-x.com/"
Use the /v1 path if required by your provider
Some OpenAI-compatible providers expose their API under /v1 (e.g., https://host/v1). If you see 404s, add /v1 to your base_url.
Using OpenAI-compatible providers
- Open marimo's Settings panel
- Navigate to the AI section
- Enter your provider's API key in the "OpenAI-Compatible" section
- Set Base URL to your provider (e.g.,
https://api.provider-x.com) - Set Model to your provider's model slug
DeepSeek¶
Use DeepSeek via its OpenAI‑compatible API.
Requirements
- DeepSeek API key
pip install openai
Configuration
[ai.models]
chat_model = "deepseek/deepseek-chat" # or "deepseek-reasoner"
[ai.open_ai_compatible]
api_key = "dsk-..."
base_url = "https://api.deepseek.com/"
xAI¶
Use Grok models via xAI's OpenAI‑compatible API.
Requirements
- xAI API key
pip install openai
Configuration
[ai.models]
chat_model = "xai/grok-2-latest"
[ai.open_ai_compatible]
api_key = "xai-..."
base_url = "https://api.x.ai/v1/"
LM Studio¶
Connect to a local model served by LM Studio's OpenAI‑compatible endpoint.
Requirements
- Install LM Studio and start its server
pip install openai
Configuration
[ai.models]
chat_model = "lmstudio/qwen2.5-coder-7b"
[ai.open_ai_compatible]
base_url = "http://127.0.0.1:1234/v1" # LM Studio server
Mistral¶
Use Mistral via its OpenAI‑compatible API.
Requirements
- Mistral API key
pip install openai
Configuration
[ai.models]
chat_model = "mistral/mistral-small-latest" # e.g., codestral-latest, mistral-large-latest
[ai.open_ai_compatible]
api_key = "mistral-..."
base_url = "https://api.mistral.ai/v1/"
Together AI¶
Access multiple hosted models via Together AI's OpenAI‑compatible API.
Requirements
- Together AI API key
pip install openai
Configuration
[ai.models]
chat_model = "together/mistralai/Mixtral-8x7B-Instruct-v0.1"
[ai.open_ai_compatible]
api_key = "tg-..."
base_url = "https://api.together.xyz/v1/"
Vercel v0¶
Use Vercel's v0 OpenAI‑compatible models for app-oriented generation.
Requirements
- v0 API key
pip install openai
Configuration
[ai.models]
chat_model = "v0/v0-1.5-md"
[ai.open_ai_compatible]
api_key = "v0-..."
base_url = "https://api.v0.dev/" # Verify the endpoint in v0 docs
See the LiteLLM provider list for more options. For non‑compatible APIs, submit a feature request.